Determined AI (HPE MLDE) 설치 - 0.28.0
오픈소스 머신러닝 플랫폼인 Determined AI 는 2021년 6월 Hewlett Packard Enterprise 에 인수 되었습니다.
K8s 상에 Helm 을 이용하여 Determined AI 최신버전인 0.28.0 (2024년 2월 14일 기준) 을 설치 해 보겠습니다.
K8s 클러스터 구성은 아래와 같습니다.
ubuntu@master1:~$ k get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master1 Ready control-plane 4h38m v1.26.5 192.168.10.102 <none> Ubuntu 22.04.3 LTS 5.15.0-94-generic containerd://1.6.4
worker1 Ready worker 4h37m v1.26.5 192.168.10.103 <none> Ubuntu 22.04.3 LTS 5.15.0-94-generic containerd://1.6.4
worker2 Ready worker 4h37m v1.26.5 192.168.10.104 <none> Ubuntu 22.04.3 LTS 5.15.0-94-generic containerd://1.6.4
CE (Community Edition) vs EE (Enterprise Edition)
Determined AI 는 AWS, GCP 와 같은 클라우드는 물론이고 Apptainer, Singularity, Enroot, Podman, Slurm/PBS 등을 지원합니다.
다만 HPC workload manager 인 Slurm 이나 PBS 를 사용하려면 Enterprise Edition 에서만 가능합니다.
NVIDIA GPU Operator
Determined AI 는 CPU 를 이용하여 AI 모델 생성이 가능하지만 학습이나 테스트 목적이 아니라면 대부분 NVIDIA GPU 를 활용할 것입니다.
K8s 상에서 NVIDIA GPU 를 사용하기 위해서는 NVIDIA GPU Operator 가 필요합니다.
설치 방법은 https://velog.io/@hpcai/NVIDIA-GPU-Operator-v23.9.1 를 참고 하세요.
Source Clone vs Helm Chart Download
K8s 상에 Helm 을 이용하여 Determined AI 를 배포하기 위해서는 Helm 차트를 다운로드 하거나 Github 에서 소스를 클론 받아 설치 하는 방법이 있습니다.
저는 아래와 같이 Github 에서 소스를 클론 받아 설치 하겠습니다.
ubuntu@master1:~$ mkdir -p ~/Work
ubuntu@master1:~$ cd ~/Work
ubuntu@master1:~/Work$ git clone -b 0.28.0 https://github.com/determined-ai/determined
Cloning into 'determined'...
remote: Enumerating objects: 184026, done.
remote: Counting objects: 100% (5710/5710), done.
remote: Compressing objects: 100% (2090/2090), done.
remote: Total 184026 (delta 4069), reused 4959 (delta 3510), pack-reused 178316
Receiving objects: 100% (184026/184026), 226.42 MiB | 10.22 MiB/s, done.
Resolving deltas: 100% (142662/142662), done.
Note: switching to '7f9b08272e58fa39a694f3993582ff2cb234b166'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
ubuntu@master1:~/Work$ cd determined/
ubuntu@master1:~/Work/determined$
Resource Pools 설정
AI 모델 생성을 위해서는 CPU, GPU 와 같은 리소스가 필요합니다. 작업마다 리소스 요구 사항이 다르므로 GPU 리소스 비용을 고려할 때 비용을 최대한 활용하려면 특정 목표에 적합한 리소스를 선택하는 것이 중요합니다. 예를 들어, H100 GPU 와 같은 고비용 시스템에서는 모델 학습을 실행하고, 텐서보드는 최소한의 리소스를 사용하는 저렴한 CPU 시스템에서 실행하기를 원할 수 있습니다. 따라서 아래와 같이 CPU Pool 과 GPU Pool 을 설정합니다.
ubuntu@master1:~/Work/determined$ tee /tmp/determined.yaml << EOF
defaultAuxResourcePool: default
defaultComputeResourcePool: gpu-pool
resourcePools:
- pool_name: default
task_container_defaults:
cpu_pod_spec:
apiVersion: v1
kind: Pod
spec:
containers:
- name: determined-container
volumeMounts:
- name: shared-fs
mountPath: /run/determined/workdir/shared_fs
volumes:
- name: shared-fs
hostPath:
path: /checkpoints
- pool_name: gpu-pool
max_aux_containers_per_agent: 1
task_container_defaults:
gpu_pod_spec:
apiVersion: v1
kind: Pod
spec:
containers:
- name: determined-container
volumeMounts:
- name: shared-fs
mountPath: /run/determined/workdir/shared_fs
volumes:
- name: shared-fs
hostPath:
path: /checkpoints
tolerations:
- key: "nvidia.com/gpu"
operator: "Equal"
value: "present"
effect: "NoSchedule"
EOF
Determined AI 설치
Helm 을 이용하여 Determined AI 를 설치합니다. 위에서 설정한 리소스 풀도 적용합니다.
ubuntu@master1:~/Work/determined$ helm upgrade determined helm/charts/determined/ \
--install \
--namespace determined \
--create-namespace \
--set useNodePortForMaster=true \
--set db.storageSize=30Gi \
--set db.cpuRequest=2 \
--set db.memRequest=2Gi \
--set maxSlotsPerPod=1 \
--set masterCpuRequest=2 \
--set masterMemRequest=2Gi \
--set defaultPassword="" \
-f /tmp/determined.yaml
Determined AI UI
ubuntu@master1:~/Work/determined$ k get svc -n determined
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
determined-db-service-determined ClusterIP 10.233.4.236 <none> 5432/TCP 3m50s
determined-master-service-determined NodePort 10.233.58.165 <none> 8080:32397/TCP 3m50s
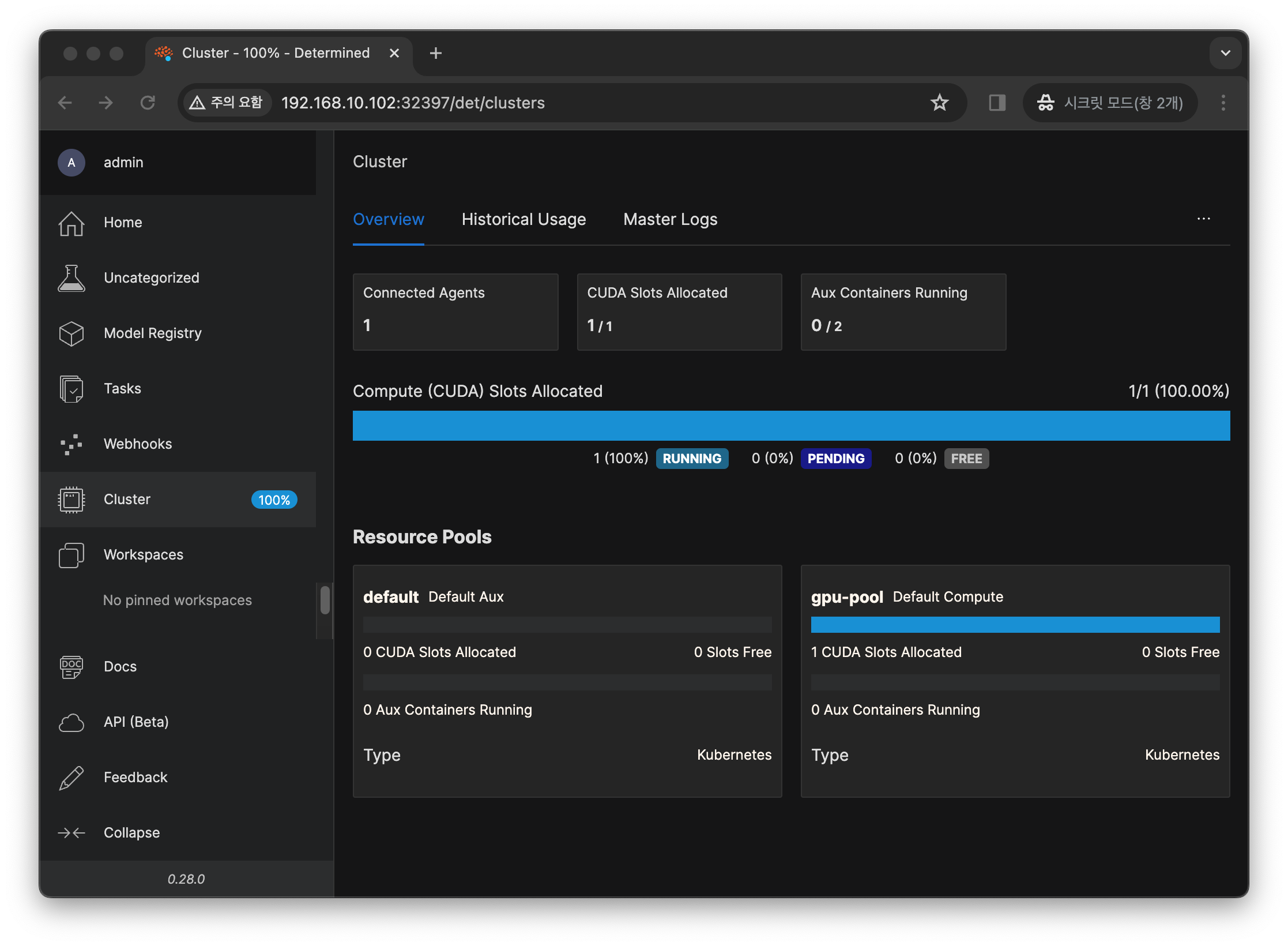
위와 같이 서비스를 확인 하여 NodePort 를 확인 합니다. 저의 경우는 32397 이 할당 되었습니다.
아래는 Determined AI 에 접속하여 클러스터 리소스 풀을 확인 하는 모습입니다.
위에서 설정한 default 와 gpu-pool 이 정상적으로 배포 되었습니다.
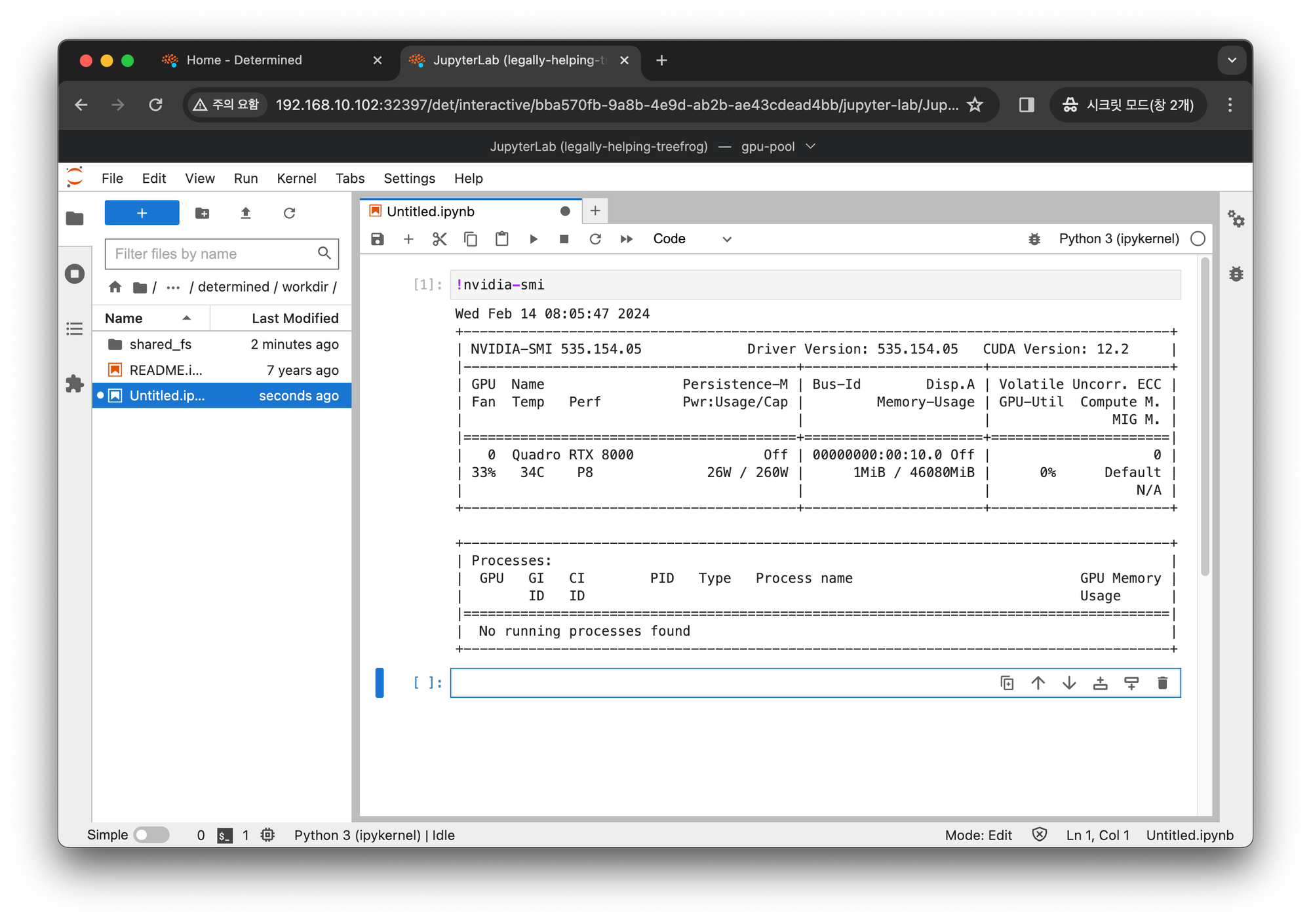
아래는 GPU Pool 에서 Jupyter Notebook 이 구동된 모습입니다.
감사합니다.
[베이넥스] DX총괄사업본부 솔루션사업부 - 김규현